
Killing the GIL: How To Use Python 3.14's Free-Threading Upgrade
The global interpreter lock (GIL) has been interfering with true parallelism in Python. That ends with Python 3.14.

For almost three decades, Python’s Global Interpreter Lock (GIL) has been the single mechanism standing between your CPU cores and real parallelism.
That changes with Python 3.14.
The new free-threaded build removes the GIL, allowing multiple threads to execute Python bytecode simultaneously. No multiprocessing, no pickle, no hacks.
In this post, I’ll:
Explain why the GIL existed and what it was protecting
Compare Python’s old concurrency models (threading, multiprocessing, asyncio)
Build Python 3.14 with the GIL disabled
Run a short multithreaded benchmark that finally scales with cores
Explain the results
Why the GIL existed in the first place
The GIL is a global mutex that historically allowed only one thread to execute Python bytecode at a time. It was there to protect CPython, the C implementation of the interpreter.
Every Python object in CPython lives on the heap as a C struct with a reference count. Each assignment or function call increments and decrements those counters constantly. If two threads updated the same object’s reference count simultaneously, you could get memory corruption or premature frees that crash the interpreter.
Adding locks around every Python object would have been complex and slow, so early CPython took the simple route: wrap the entire interpreter in one global lock. That made single-threaded execution safe, but prevented true multithreading for CPU-bound workloads.
How concurrency previously worked
Before 3.14, Python offered three main concurrency models, each with trade-offs:
threading (old): uses real OS threads, but only one can execute Python bytecode at a time because of the GIL. Good for I/O, useless for parallel CPU work.
multiprocessing: spawns multiple processes, each with its own interpreter and GIL. True parallelism, but expensive, requiring separate memory, pickling overhead, and slower process startup.
asyncio (green threads): runs everything cooperatively on one thread. Excellent for high-concurrency I/O, but it never uses more than one core.
With Python 3.14’s free-threaded build, threading becomes the best of all worlds: true parallelism across cores, shared memory without serialization, and minimal overhead.
Building Python 3.14 without the GIL
Compile it yourself:
git clone https://github.com/python/cpython
cd cpython
git checkout v3.14.0
./configure --prefix=$HOME/.py-314-ft --disable-gil
make -j && make install
$HOME/.py-314-ft/bin/python3 -VOr with pyenv:
pyenv uninstall -f 3.14.0 || true
PYTHON_CONFIGURE_OPTS=”--disable-gil” pyenv install 3.14.0
pyenv local 3.14.0Verify that you’re running a free-threaded build:
python3 - <<’PY’
import sys
print(”Free-threaded build:”, not sys._is_gil_enabled())
PYYou want: Free-threaded build: True.
Running a realistic multithreaded benchmark
Here’s a bit-optimized N-Queens solver. You can also download the repo on GitHub. It’s already efficient and CPU-bound, a good test of whether threads can finally scale.
# nqueens.py
import threading, time
def solve_row(n, cols=0, diags1=0, diags2=0, row=0):
if row == n: return 1
count = 0
free = (~(cols | diags1 | diags2)) & ((1 << n) - 1)
while free:
bit = free & -free
free -= bit
count += solve_row(
n, cols|bit, (diags1|bit)<<1, (diags2|bit)>>1, row+1
)
return count
def solve_threaded(n, n_threads):
first_row = [(1 << c) for c in range(n)]
chunks = [first_row[i::n_threads] for i in range(n_threads)]
total = 0
lock = threading.Lock()
def work(chunk):
nonlocal total
local = 0
for bit in chunk:
local += solve_row(
n, cols=bit, diags1=bit<<1, diags2=bit>>1, row=1
)
with lock:
total += local
threads = [threading.Thread(target=work, args=(c,)) for c in chunks]
for t in threads: t.start()
for t in threads: t.join()
return total
if __name__ == “__main__”:
for threads in (1, 2, 4, 8):
t0 = time.perf_counter()
solve_threaded(14, threads)
dt = time.perf_counter() - t0
print(f”threads={threads:<2} time={dt:.2f}s”)Run it once with standard CPython 3.14 (GIL on) and once with your free-threaded build. With the GIL, all runs take about the same time. With the free-threaded build, performance improves almost linearly with thread count.
Results
Example benchmark:
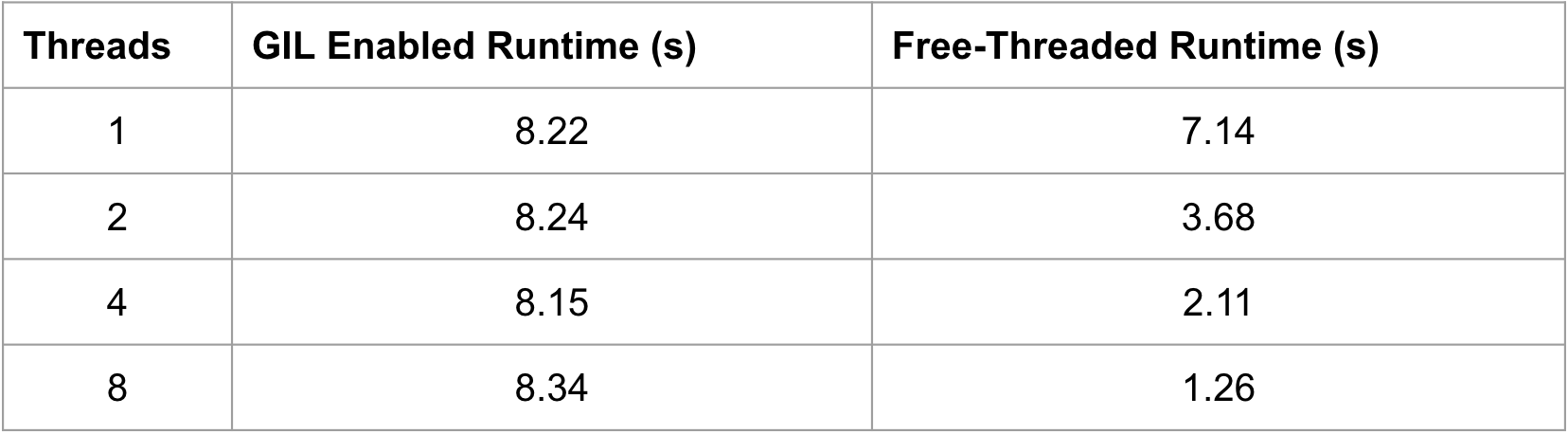
That’s an ~8x speed-up without changing a single line of logic - just running under the free-threaded interpreter.
Caveats:
C extensions: any binary package must be recompiled for free-threading, or it might quietly re-enable the GIL.
Thread safety: without the GIL, race conditions are real. Protect shared state with locks, queues, or immutable data.
Single-thread overhead: expect a 5-10% slowdown for purely single-threaded scripts due to atomic ops and internal locks.
Closing thoughts
The GIL made CPython simple and safe to implement, but it locked Python to a single core.
With Python 3.14, that trade-off is gone. For the first time, standard Python threads can run in true parallel on modern CPUs.
So go ahead and kill the GIL, and let me know how it works for you.